Tech
Comparing Image Rendering with Midjourney, Stable Diffusion 2, and Dall-E 2


You’ll find all kinds of AI image generators out there, each specializing in its own style and technique of rendering images, including our own, Let’s Enhance Image Generator, which we just launched (psst, check it out, it’s really cool). But three of the most popular ones out there are Dall-E (1, 2, and Mini), Midjourney, and Stable Diffusion 2.
We wanted to see how these top AI platforms compare when you give them the same text prompts.
So, here are the results of our little experiment, which may shed some light on how these image generators work, what prompts they focus on, and what results you can expect from them.
Interior Design

When it comes to interior design, there are a ton of stock images. All three image generators demonstrated a very accurate replication of modern Scandinavian images, with that signature white and gray color palette, as well as the wood and biophilic accents.
It is very likely that all three AI generators were fed the same stock images of Scandinavian interiors, hence why they could imitate them so accurately.
Festive Shop Exterior

Next up we have a text prompt that asks the AI platforms to generate images of festive exterior facades of shops in an old winter town. This is where the results began to vary.
Dall-E 2 and Stable Diffusion 2 seemed to put a greater emphasis on the “shop” text prompt, as both images feature the facade of a shop, with a window looking into the interior, along with old-fashioned lanterns on the outside. Stable Diffusion 2, more so than Dall-E 2, put some extra emphasis on the winter decorations, with ribbon-like objects decorating the wall and window.
Midjourney took a more abstract approach to the text prompt, as there really is no shop facade in sight, but rather a more atmospheric image of old-fashioned lanterns scattered across the background. This is most likely the text prompt “Christmas decorations in medieval town” receiving more focus. So while there is no distinct shop window in the image, Midjourney was able to replicate the general visualization of a medieval town during the winter with lamps.
Futuristic Arctic Vehicle

On the topic of winter and snow, the next prompt that was fed to the AI image generators was to create a futuristic rally vehicle in Antarctica.
Dall-E and SD created a photo-realistic image of a vehicle, with two different approaches. Stable Diffusion 2 seemed to have emphasized the “rally” text prompt, by creating a car that resembles a small car driven during rallies. Dall-E 2 clearly emphasized the text prompt “exploring”, as it was inspired by Mars exploration vehicle designs, with a larger set of tires and higher suspension.
Midjourney went all-in with the “rally vehicle” text prompt, as there aren’t many details in the vehicle that would indicate that it is used for exploration. In fact, it most likely first generated a futuristic rally car, as the text prompt dictated, after which it generated an arctic background behind it.
It’s also worth noting, that, unlike the other two generators, Midjourney did not go for a photo-realistic approach, instead generating an image that looks almost like a piece of vintage concept art.
Nightly Gas Station Pixel Art

Another experiment we decided to pull off, was to see how successfully the three generators can work with pixel art.
The most obvious difference between the three is that, unlike its two counterparts, Dall-E 2 once again aimed to create something that is both 8-bit and also photo-realistic. As a result, the artwork seems to imitate a photo of an actual gas station, but at a very low resolution. There is no blockiness in the photo and a lot of curvatures, two details not indicative of an 8-bit design.
On the other hand, Midjourney and Stable Diffusion 2 successfully recreated an 8-bit gas station at night. Midjourney was especially successful with this art style, as, upon a closer examination of the image, you can definitely see a lot of blockiness and sharp angles.
Neon Anime Character

One of the experiments where all three generators delivered very different results, was when they were asked to render images of a neon anime character, inspired by a video game character. The text prompt not only included the style of the image, but also famous names of anime and fantasy artists.
Dall-E 2 was heavily inspired by the cartoony art style of the video game “Overwatch”, which was included in the text prompt. It also heavily emphasized the “neon ambiance” text prompt and was likely inspired by the manga/anime artwork of Mokato Shinkai and Ilya Kuvshino.
Midjourney used the “neon” text prompt as an accent, as the image looks more 3D than the others. This could be attributed to the “unreal engine” text prompt (UE is a 3D engine used by game developers), as well as an overall cyberpunk style. The sharpness of the eyes and brow, as well as the small nose poking out of the face, seems to replicate the artwork of Lois van Baarle, one of the artists named in the text prompt.
Aspects of Lois van Baarle’s style can also be found in the Stable Diffusion 2 rendering, with the large, expressive eyes, as well as the nose and hair. Unlike the other two generated images, SD seemed to put less emphasis on “neon” and a more detailed urban landscape, which seems to mirror the fantasy landscapes of Artem “rhads” Chebokha, who was also featured in the text prompt.
Anime Boy Drinking Coffee

While on the topic of anime art, another prompt we decided to test out is an anime boy drinking coffee, with the style of Makoto Shinkar and Studio Ghibli, as well as some inspiration from the video game, Genshin Impact. This is another case where all three image generators created something entirely different from one another.
Dall-E 2 seemed to be more inspired by anime, but with a heavier emphasis on Genshin Impact. This contrasts the SD rendering, which imitated the style of Studio Ghibli’s 80’s anime films. The high contrast between light and shadows, as well as the more muted colors, make it seem like a frame out of an old anime film.
Midjourney seemed to be the odd one out, as it generated an image that does not imitate any sort of anime, but seems to emphasize the “acrylic text prompt”. In fact, the “boy drinking coffee” prompt seems to have been overlooked by the AI, as the boy is not holding the coffee since the cup is in the foreground. It almost seems as if focused more on rendering an image that looks acrylic than anime.
Two Men Drinking Coffee

Speaking of coffee, here’s another interesting experiment on how the three AI image generators work. The text prompt was much simpler than the previous ones, as it asked the AI to generate an image of two men in suits drinking coffee.
Right off the bat, it’s easy to tell that both Dall-E 2 and Stable Diffusion 2 used stock images as inspiration, as both have two men doing that signature “stock image smile” in both photos. Dall-E 2 is most notable, as upon first glance, it looks almost indiscernible from an actual stock photo.
Stable Diffusion 2 also went for a more stock image aesthetic, though with less detail and from a slightly farther angle. Midjourney was drastically different from the other two, as it seemed to be inspired by impressionist paintings, with two men drinking coffee. It’s important to note, that the Midjourney render may have emphasized the “old Italian street” part of the “Two men sitting at cafe on old Italian street”, hence why it generated a far less modern rendering of the prompt than the other two generators.
Photoshoot Featuring Robert De Niro

This is where we get to the bane of most AI image generators which is to render the faces of famous people. The name we decided to use was one we were sure would have many photos on Google: legendary actor Robert De Niro.
If Mr. De Niro were to see the renderings, he would either be impressed by how a few of them were able to imitate various signature aspects of his appearance, and not recognize himself in a few others.
The most visually successful rendering of the actor seems to be done by Stable Diffusion 2. Both renderings successfully accentuated the actor’s distinct facial features, such as the shape of his nose, hairline, and eyebrows. The other renderings also attempt to recreate the actor's facial features but seem to have trouble rendering them.
French Fries and Some Fashion

We also made an attempt to blend together photography and painting, the subject being a magazine cover girl with french fry trees. We didn’t get french fries growing on trees (unfortunately), but we did get something almost as interesting.
Dall-E 2 placed a barbie-looking model behind a scoop of fries, with a garden landscape as the background. It seems as though the “art painting by Ignasi Monreal” was ignored and Dall-E 2 went for something more resembling a photograph (as we’ve seen it do many times).
Stable Diffusion 2 took a more “artistic” approach with how it incorporated the “french fries trees” text prompt. In fact, it seems as though it modeled the french fries into the model’s skirt, creating a very unique aesthetic. It also seemed to imitate the contemporary classical style of Ignasi Monreal.
Midjourney fully relied on the text prompt “magazine girl in garden Gucci” and Ignasi Monreal’s surreal paintings. It’s important to note, that there is no garden in sight and the AI replaced it with a few twigs and leaves. Additionally, there are no french fries in the image instead, what look to be hamburger buns and slices of tomato. It is likely that french fries often show up in images with burgers, hence why the AI felt the need to include them too.
French Fries Again, But This Time Next to a Pool

We weren’t done with french fries just yet. There was still a lot more that needed to be tested with the 3 AI platforms. This prompt also asked for a magazine cover-style image that includes french fries, but this time with a pool.
Much like the previous prompt, Midjourney once again, put plenty of emphasis on the “art painting” text prompt and generated an image that is reminiscent of an oil painting. The fries are also inside a clay pot very similar to classical paintings of fruit, which are usually placed inside similar containers. So, it is safe to assume that Midjourney used classical paintings as the primary reference for its rendering.
Dall-E 2 took full advantage of the “photoreal” text prompt and created a colorful image of a scoop of fries that fell into a pool, even replicating the ripples and water distortion. The french fry scoop is also made to look very realistic, right down to the little curve at its bottom, something that you can find in many fast food restaurants.
Stable Diffusion 2 took a very different approach, as it seems as though the “magazine French fries in pool” text prompt had a large influence on the rendering. The french fries, which appear to be inside a glass, are floating inside a body of water, not a pool. The background is also matte red, which is most likely due to the “magazine” text prompt.
Abstract Tron Landscape
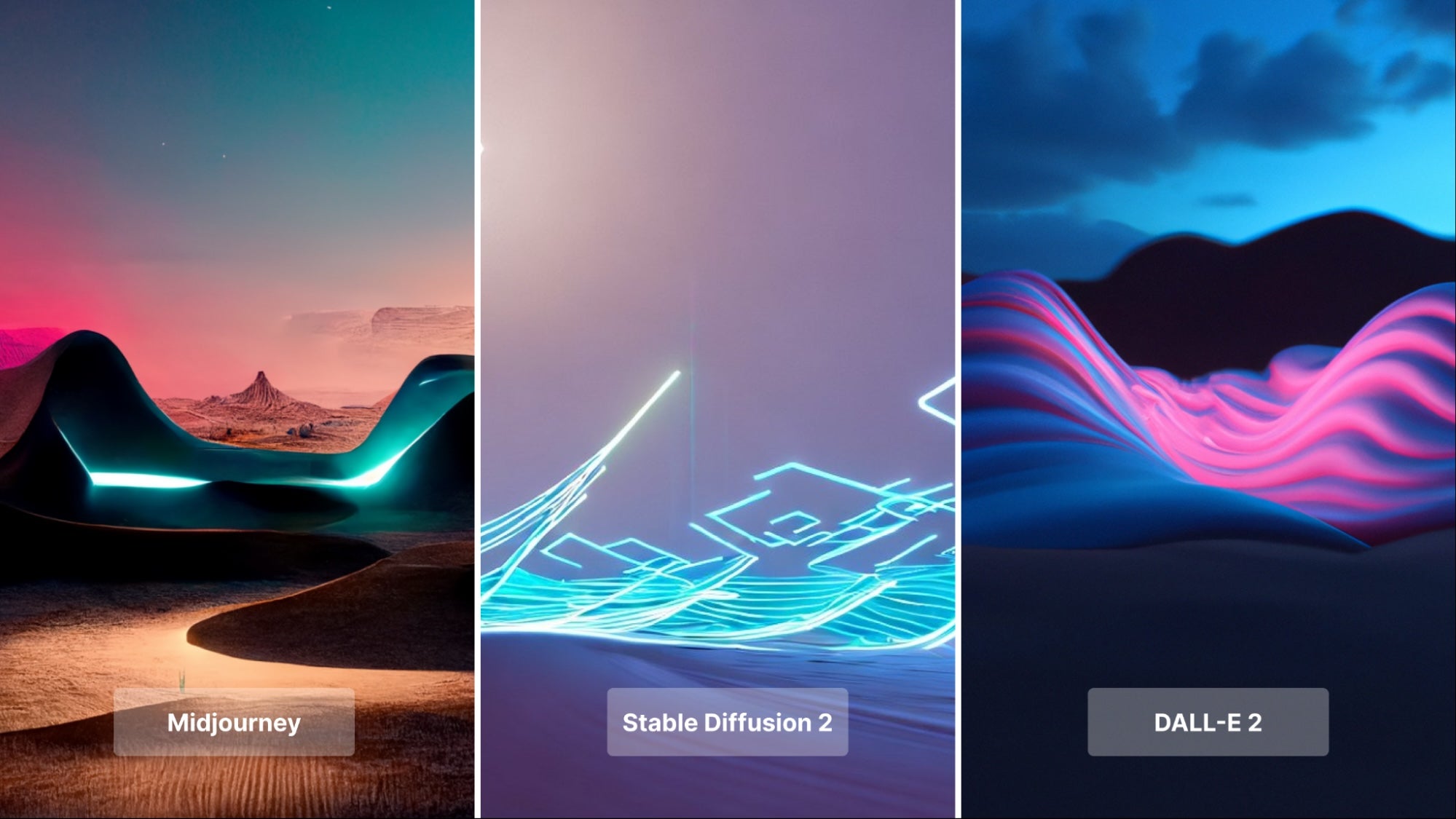
We wanted to finish off with something a little more abstract. Since we already had some prompts with neon, we decided to try out a landscape with an “outrun” aesthetic, similar to that of Tron. In fact, we included the word “Tron” in the text prompt and this had a major impact on Midjourney’s and Stable Diffusion’s renderings, as both feature bright blue LED lights, one of the most popular features of the Tron aesthetic.
Midjourney’s rendering was exceptionally detailed, with a desert canyon landscape (also in the prompt), with a LED light accent. And while the AI platform puts more emphasis on generating a desert canyon than something from Tron, the lights and shadows create a very attractive contrast.
Stable Diffusion 2 created a far more abstract image, with the LED lights and desert landscape clearly separated. SD2 also rendered far more angular geometry than the other two, as this is something very common in the Tron aesthetic.
Dall-E 2 was the odd one out this time, as it seems to have ignored the “Tron” text prompt, and instead, created a neon desert environment that imitates a low-poly desert canyon. There are none of those bright blue LED lights that the other two AI platforms created, imitating the Tron aesthetic, but the bright purple neon lighting in the center of the image tells us, that the AI definitely inspired by an 80s aesthetic, most likely the aforementioned “outrun”, even though it was not in the text prompt.
Summary of Our Findings
We are well aware that each AI platform is different and text prompts affect the results in wildly different ways, whether you’re using Dall-E 2, Stable Diffusion 2, or Midjourney. But some consistencies we found may hint at how each platform works and how you should use them.
Dall-E 2, with the exception of a few renderings, seems to favor photo-realism. This means it looks to render images that look indistinguishable from a real photo. Now, with the current technology, this doesn’t always work out as the tech is still rather fresh, but with the right text prompts, you could render very realistic images, such as Dall-E 2’s french fries in a pool or arctic explorer vehicle.
Midjourney definitely favors digital art and more abstract or stylized renderings. Most notable examples of this are the model with french fries and the “two men drinking coffee”, which was vastly different from the renderings of the other two platforms.
Stable Diffusion 2 seems to be a middle ground between Dall-E 2’s photorealism and Midjourney’s abstract and artistic renderings. It can do minimal magazine covers with french fries, but also render very accurate images of Robert De Niro.
Check Out the Let's Enhance Image Generator
One thing most AI image generators have in common is that they work with a resolution cap. Since they are used by millions of people, to reduce the strain on these AI platforms, the developers limit the resolution of the rendering.
You can use Let's Enhance to upscale AI-generated images. Even if your rendering is small, the AI-powered software of Let's Enhance will enhance your AI-rendered image and increase its resolution. Check out our tutorial below to see how this can be done.
Also, check out our own AI image generator that renders your desired image using very user-friendly settings. You can also enhance and upscale your generated image on the platform itself, making it a one-stop-shop for your AI image renderings.
Need this at scale?
Process thousands of images via API, or let our team handle it for you.



Claid.ai
December 24, 2023